파이썬 기본 문제들(틀린부분)

문자열은 1,0이 아닌 문자열일 뿐임.
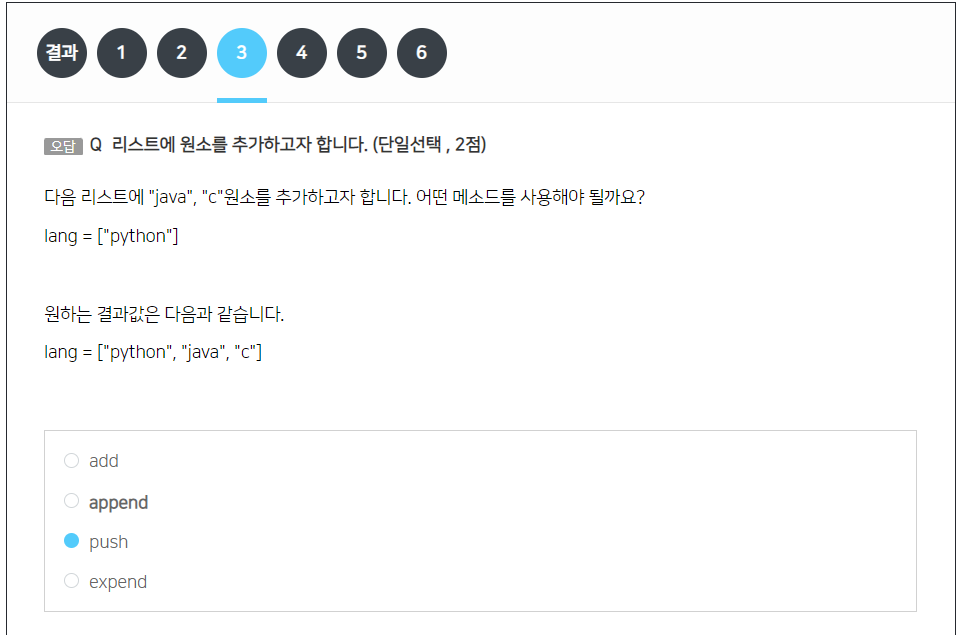
push는 아래의 예시처럼 뒤에 추가하는 건 맞지만, 출력을 더해진 길이값만을 출력.
const count = animals.push('cows');
console.log(count);
// Expected output: 4
근데 중요한건... push()는 파이썬에 없다.ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
append만이 답이다.

제어문(조건문, 반복문)
# enumerate를 사용하면 인덱스 번호와 원소를 같이 가져올 수 있습니다.
for i, val in enumerate(lang):
print(i, val)
#결과 : 0 pyhon
틀린이유가 부주의 때문이지만, 아래의 메서드들을 몰랐고, 헷갈려하므로 틀리길 잘했다는 생각이다.
슬라이싱, startswith, in을 통해 문자열에 경기가 있는지 확인하기
# 슬라이싱으로 문자 가져오기
address:[:2]
# 결과 : '경기'
# startswith를 사용하면 특정 문자가 포함되는지 여부를 확인할 수 있습니다.
address.startswith("경기")
# 결과 : True
# in을 사용하게 되면 특정 문자열을 포함하고 있는지 여부를 확인할 수 있습니다.
"경기" in address
# 결과 : True
pandas 사용하기

시작 선언. 데이터 프레임 만들기(2차원 자료구조)

1차원 배열의 시리즈
Series는 모든 데이터 유형 (정수, 문자열, 부동 소수점 숫자, Python 객체 등)을 보유 할 수있는 1차원 레이블이 지정된 배열이다. 이때, 축 레이블을 총칭하여 인덱스라고 부른다.

[그림 1-1] 시리즈와 데이터프레임 구조
<출처: https://www.kdnuggets.com/2017/01/pandas-cheat-sheet.html>
시리즈 만들기
시리즈를 만드는 방법은 다음과 같다.

기본 입,출력
이렇게 두 열을 같이 쓰고자 하면 에러발생

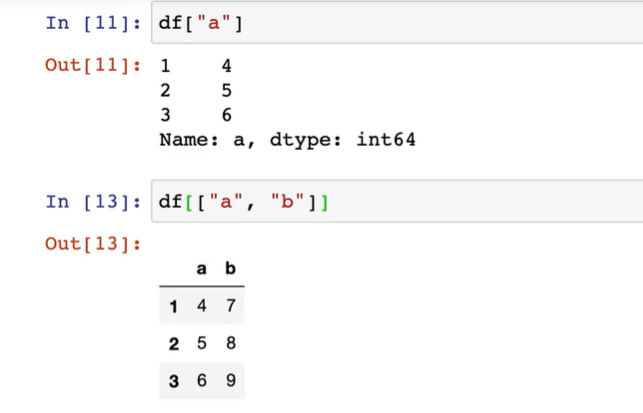
한 개의 ["컬럼명"] 시리즈 출력.
두 개의 [["컬럼명1","컬럼명2",....]]감싸는 코드는 데이터 프레임 형태를 가져온다.

다양한 메서드(count, len)
4,5,6이라는 값들의 빈도수를 출력해줌.

1.df의 길이를 출력.
2. a로 분류되는 열의 값들을 가져옴

순서 정리 메서드
a col( a열값들의 모임)을기준으로 b,c의 값들을 정렬후(오름차순)

역순(내림차순)으로 가져와라는 뜻.

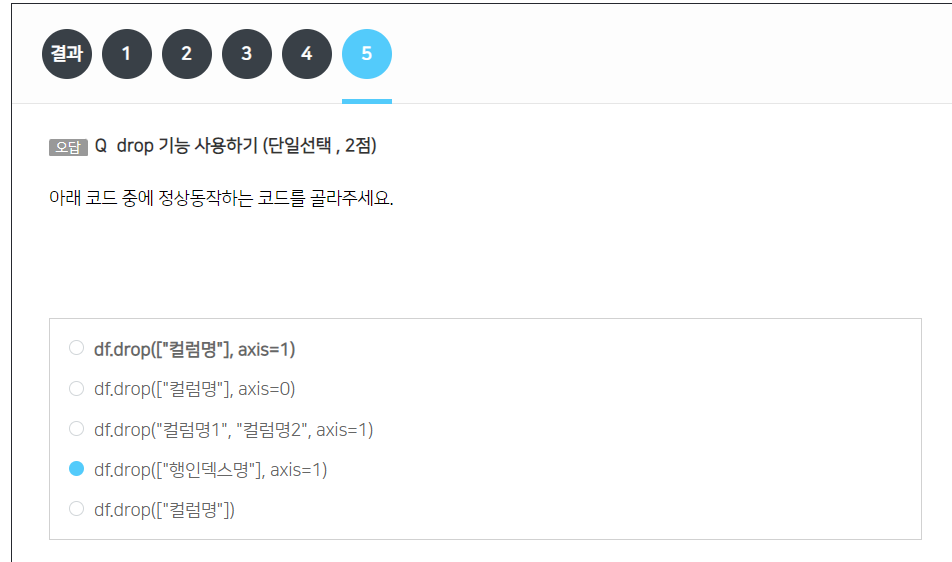
삭제
axis는 행을 의미
drop(["컬럼명"], axis=1)은 행을 기준으로 삭제하기에 선언이 필요하다.

다시 df를 입력해서 출력해보면 반영이 안되기에
df = df.drop~
윗 식처럼 변수안에 담은 뒤에, 출력해줘야 반영된다.

평균, 합, 갯수 , 퍼센트 구하기
a라는 col를 기준으로 b까지의 모든 값들을 묶는 groupby(기준 col)[원하는 col 한개]
평균, 합, 갯수를 구할 수 있다.


값은 값 두개가 있는 경우(ex, a값이 두개)
그 값을 평균을 내서 하나의 값들로만 나타내고,
다른 중복되지 않은 숫자는 그대로 값을 나타낸다.

데이터 시각화

. + tab 을 통해 다양한 시각화로 표현이 가능하다.


'📊python > 파이썬, 데이터분석' 카테고리의 다른 글
| 파이썬 데이터분석(4)[numpy 기초][pycharm 기준] (0) | 2023.02.20 |
|---|---|
| 파이썬 데이터분석(3)[파일 경로 설정] (0) | 2023.02.20 |
| 파이썬 데이터분석(1)[주피터 가상환경 설정 및 주피터 실행, 단축키] (0) | 2023.02.19 |
| 파이썬 기본이론 정리(5) [입출력, input 사용, 출력서식, 메서드] (0) | 2023.02.15 |
| 파이썬 기본이론 정리(4)[함수선언, 가변선언, 지역,전역변수] (0) | 2023.02.15 |